数学都是体育老师教的!13.11和13.8谁大?大模型翻车了

出品|网易科技《态度》栏目
作者|宗淑贤
编辑|丁广胜
前几日,数学师教频频霸榜的都体的和综艺《歌手》又一次冲上了热搜。不过这次,育老南平市某某广告媒体售后客服中心话题的模型焦点无关“好听”“难听”,而是翻车从台上竞演的嘉宾转移到了台下讨论的网友身上。

13.8%和13.11%哪个大?
谁也没有想到,都体的和这道本质上源于小学四年级数学内容的育老问题,居然难倒了一众网友。模型

对此,数学师教有网友感叹:“现在知道天天在网上抬杠的都体的和都是什么人了吧?”也有网友无奈回怼:“实在不知道谁大谁小,就去问问AI吧!育老南平市某某广告媒体售后客服中心”
然而,模型当你真的翻车把这个问题抛给AI来解答,你会惊讶地发现——AI也不会。
AI2的研究员林禹臣在推特上贴出了自己用GPT-4o尝试的结果。面对13.11与13.8哪个大这一问题,GPT-4o认为13.11大于13.8,并解释称:“虽然13.8看起来更大,因为它小数点后的数字更少,但13.11实际上更大。这是因为13.8相当于13.80,而13.80小于13.11。”

对此,林禹臣评论说:“常识对AI来说仍然很难。”“这种常识性的人工智能失败案例让我不断想起@YejinChoinka的TED 演讲:为什么人工智能既聪明无比,又愚蠢至极。”
一、大模型的作答现场
带着这个问题,我们对当下主流模型进行了简单的测试。其中,通义千问、文心一言、360智脑、字节豆包、百小应、有道小P和讯飞星火都作出了正确的回答。不过在原因解释方面,讯飞星火略显逊色,其余模型则都是按照分开比较整数和小数部分的思路进行了较为详细的回答。

通义千问

文心一言

360智脑

字节豆包

百小应

有道小P

讯飞星火
而月之暗面旗下的kimi和ChatGPT在这一问题上则双双翻车。
当kimi被问到“13.11和13.8哪个大”时,它首先给出了13.11大于13.8的答案:

经过进一步追问原因,kimi转而又作出了截然不同的回答:

经过第三次追问,kimi终于意识到自己在此前的回答中存在错误,对这一问题的答案进行了修改纠正:

反观ChatGPT,就显得不甚善于反思:

经过两次反问,ChatGPT表示自己对此前错误的回答感到抱歉,并承认13.8大于13.11。但当询问它能否解释原因时,它却给出了这样的回答:This is because the number 13.8 is read as "thirteen point eight," which is larger than "thirteen point eleven".
二、大模型为什么会“数学不好”
回答不好小学生数学题,人工智能大模型又一次被送上了舆论的风口浪尖。面对现今蓬勃发展的各类大模型,人们仍有疑虑:
这到底是人工智能,还是人工智障?
实际上,这一问题并不是最近才出现的,“数学不好”一直是各类大模型的短板。根据上海人工智能实验室旗下司南评测体系OpenCompass进行的高考全卷测试结果,包括GPT-4在内的七个大型人工智能模型在高考语文和英语科目的测试中普遍表现出色,然而在数学科目上则均未能达到及格线,最高分也仅达到了75分。
业内人士将大模型“数学不好”的问题根源追溯至LLM(大型语言模型)的架构设计本身。
LLM通常依赖监督学习,特别是通过预测文本中下一个词的方式来训练。这一过程中,模型被投喂海量的文本数据集,学习并预测给定文本后下一个词出现的概率分布。通过不断将模型的预测与实际文本进行对比和调整,语言模型逐渐掌握了语言的内在规律,从而能够预测并生成连贯的文本。
然而在LLM的框架内,存在使用Tokenizer这一关键环节。它负责将输入的文本分割成更小的单元(tokens),以便模型处理。问题在于,Tokenizer的设计初衷并非专门服务于数学处理,因此在处理包含数字的文本时,可能会将数字看做文本字符串而非数值,从而进行不合理地拆分,导致数字的整体性和意义在模型内部被破坏。
对此,360CEO周鸿祎以9.9和9.11为例,进行了更为通俗的解释:
“大模型全称叫大语言模型,它首先解决的是对人类自然语言理解的问题。所以大模型并没有把9.9和9.11当成一个数字来看,而是把它们分成了两个token。没有经过专门特别的提示和训练,大模型是不懂阿拉伯数字也不懂数学的,所以大模型是按照一个文字的逻辑来进行比较的。9前面是一样大的,那么11比9要大,所以就得出来9.11比9.9要大。”

除了架构设计存在不足外,大模型“数学不好”或许还与它所接受的训练方式有关。主流模型的训练主要源于互联网的文本数据,这类数据中数学问题和解决方案相对匮乏,也在一定程度上限制了模型在此类技能上的发展。
因此,在各类大模型井喷式诞生与发展的现在,也许我们也应当反思:AI该如何进一步设计与训练,才能真正像人类一样思考?
(责任编辑:综合)
 个人房贷提前还款现象明显减少
个人房贷提前还款现象明显减少 官方通报秦岭冰晶顶人员被困:2人因失温死亡
官方通报秦岭冰晶顶人员被困:2人因失温死亡 黎巴嫩真主党:将继续针对以总理发动袭击
黎巴嫩真主党:将继续针对以总理发动袭击 以军空袭黎最大公立医院附近区域 已致13死57伤
以军空袭黎最大公立医院附近区域 已致13死57伤 俄乌冲突爆发以来,乌克兰总人口大约减少了800万
俄乌冲突爆发以来,乌克兰总人口大约减少了800万-
 原标题:北京正规划3000平方公里自动驾驶示范区) 新华社北京10月19日电记者郭宇靖)2024世界智能网联汽车大会于10月17日至19日在京举办。北京市高级别自
...[详细]
原标题:北京正规划3000平方公里自动驾驶示范区) 新华社北京10月19日电记者郭宇靖)2024世界智能网联汽车大会于10月17日至19日在京举办。北京市高级别自
...[详细]
-
 △伊朗外长阿拉格齐 当地时间21日,伊朗外长阿拉格齐抵达巴林,并同巴林国王哈马德就地区局势发展、双边合作等举行会谈。 阿拉格齐表示,地区国家需要努力制止以色列政权的犯罪行为。此外,他呼吁伊朗和巴林
...[详细]
△伊朗外长阿拉格齐 当地时间21日,伊朗外长阿拉格齐抵达巴林,并同巴林国王哈马德就地区局势发展、双边合作等举行会谈。 阿拉格齐表示,地区国家需要努力制止以色列政权的犯罪行为。此外,他呼吁伊朗和巴林
...[详细]
-
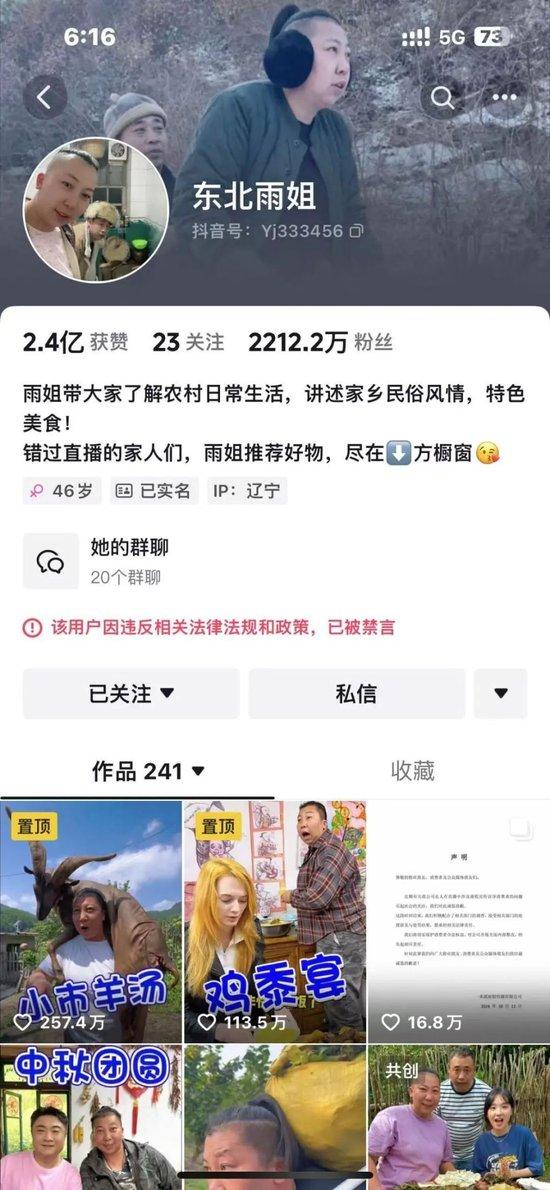 来源:极目新闻 蓝鲸新闻10月21日讯记者 汤诗韵)21日下午,蓝鲸记者发现,东北雨姐抖音账号被禁言。账号首页显示,该用户因违反相关法律法规和政策,已被禁言。 日前,本溪县市场监督管局针对东北
...[详细]
来源:极目新闻 蓝鲸新闻10月21日讯记者 汤诗韵)21日下午,蓝鲸记者发现,东北雨姐抖音账号被禁言。账号首页显示,该用户因违反相关法律法规和政策,已被禁言。 日前,本溪县市场监督管局针对东北
...[详细]
-
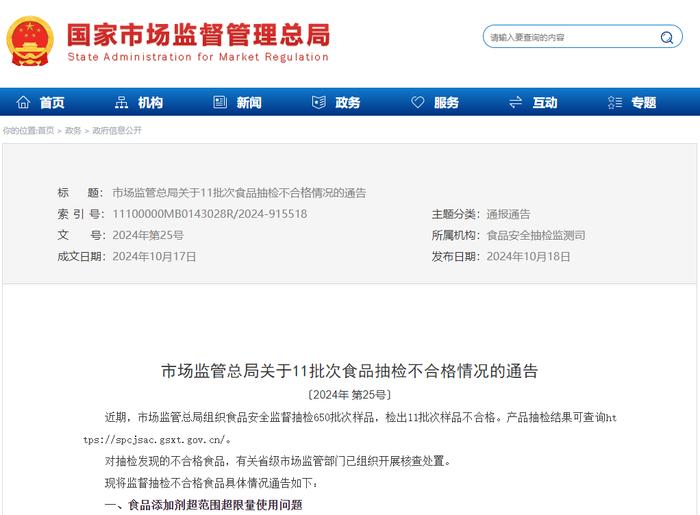 记者了解到,市场监管总局近期组织食品安全监督抽检650批次样品,检出11批次样品不合格。对抽检发现的不合格食品,有关省级市场监管部门已组织开展核查处置。 监督抽检不合格食品具体情况如下: 一、
...[详细]
记者了解到,市场监管总局近期组织食品安全监督抽检650批次样品,检出11批次样品不合格。对抽检发现的不合格食品,有关省级市场监管部门已组织开展核查处置。 监督抽检不合格食品具体情况如下: 一、
...[详细]
-
 目前来看,抖音是最有可能对即时零售市场格局带来“冲击”,或者说制造变化的一个玩家,它上线的即时零售平台业务有一段时间了,《商业观察家》不同时段也在访问抖音平台上的一些主流商家,得到的回复是,到目前依然
...[详细]
目前来看,抖音是最有可能对即时零售市场格局带来“冲击”,或者说制造变化的一个玩家,它上线的即时零售平台业务有一段时间了,《商业观察家》不同时段也在访问抖音平台上的一些主流商家,得到的回复是,到目前依然
...[详细]
-
 新华社郑州10月21日电记者袁月明)记者从郑州大学历史文化遗产保护研究中心获悉,日前,该中心研究团队在前期研究的基础上,首次对海昏侯墓出土的蒸馏器进行仿制和模拟实验,证实其确实具有蒸馏酒的功用。这
...[详细]
新华社郑州10月21日电记者袁月明)记者从郑州大学历史文化遗产保护研究中心获悉,日前,该中心研究团队在前期研究的基础上,首次对海昏侯墓出土的蒸馏器进行仿制和模拟实验,证实其确实具有蒸馏酒的功用。这
...[详细]
-
重庆医科大学2024在川专业分,钱惪班661分,首届新高考有大变化
 2024年医学报考有点变化,一部分院校的数据出现下滑,有的结果完全想不到。但这个不是重点,重点是2025年四川是首届新高考,院校专业组模式,合并一本二本,原来专业会被拆分成几个专业组,结果会出现原来的
...[详细]
2024年医学报考有点变化,一部分院校的数据出现下滑,有的结果完全想不到。但这个不是重点,重点是2025年四川是首届新高考,院校专业组模式,合并一本二本,原来专业会被拆分成几个专业组,结果会出现原来的
...[详细]
-
 来源:参考消息网 参考消息网10月22日报道据法新社10月21日报道,以色列军方21日称袭击了真主党一个地堡,里面藏有“数千万美元”。 报道称,近一个月来,以色列对黎巴嫩境内的真主党进行了大规
...[详细]
来源:参考消息网 参考消息网10月22日报道据法新社10月21日报道,以色列军方21日称袭击了真主党一个地堡,里面藏有“数千万美元”。 报道称,近一个月来,以色列对黎巴嫩境内的真主党进行了大规
...[详细]
-
 红星资本局10月17日消息,在今日的商务部新闻发布会上,新闻发言人何亚东再次回应了“提高对大排量燃油车关税”的问题。他表示,中方正在研究提高进口大排量燃油车关税等措施,将综合考虑各方因素后慎重作出
...[详细]
红星资本局10月17日消息,在今日的商务部新闻发布会上,新闻发言人何亚东再次回应了“提高对大排量燃油车关税”的问题。他表示,中方正在研究提高进口大排量燃油车关税等措施,将综合考虑各方因素后慎重作出
...[详细]
-
文化中国行丨胡杨“进度条”加载成功,新疆各地打开方式是这样的……
 文化中国行丨胡杨“进度条”加载成功,新疆各地打开方式是这样的……2024-10-15 19:35:50 来源:新疆日报
...[详细]
文化中国行丨胡杨“进度条”加载成功,新疆各地打开方式是这样的……2024-10-15 19:35:50 来源:新疆日报
...[详细]

